《Redis设计与实现》RDB和AOF持久化
本文最后更新于 2025年8月29日 下午
RDB持久化
Redis是一个内存数据库,数据都被保存在内存中。因此如果没有一个合适的方法将数据保存到磁盘中的话,服务器进程的任何可能的退出或崩溃都会导致内部数据全部丢失。因此需要一个方法将数据库中的内容保存到磁盘中。而Redis便是使用了RDB持久化的方式将数据保存在磁盘中,以供服务器的保存与还原。
RDB文件是一个经过压缩的二进制文件。
RDB文件的创建与载入
两个命令可以用于生成RDB文件:SAVE和BGSAVE。实际上顾名思义
SAVE:保存数据库数据的时候会阻塞Redis服务器进程- 底层逻辑中,该命令不会
fork一个子进程。
- 底层逻辑中,该命令不会
BGSAVE:Backgroud Save,可以看出在这个命令下Redis会用一个后台程序来保存数据库数据。实际上就是Redis会派生一个子进程,由子进程负责创建RDB文件。- 底层逻辑中,该命令会首先
fork一个子进程。 - 由这一点可以看出,Redis并不是一个纯粹的单线程程序,它实际上的单线程是针对于数据库数据执行的任务流程。也就是说,在操作数据的层面上来说,Redis是一个纯粹的单线程,因此不需要担心数据一致性和死锁的问题。
- 底层逻辑中,该命令会首先
服务器数据库的备份日志有两种RDB和AOF,充当这两个日志备份的指令有SAVE, BGSAVE, BGREWRITEAOF,它们三个在Redis服务器中同一时间只能执行一个,不允许任何的同时执行。
SAVE与BGSAVE:任意一个的执行期间,客户端发送的另一个指令都会被服务器拒绝。两个相同的SAVE和BGSAVE指令也是不允许的。因为他们可能会产生竞争条件。SAVE, BGSAVE与BGREWRITEAOF:SAVE, BGSAVE指令运行过程中,客户端发送的BGREWRITEAOF指令会在SAVE, BGSAVE指令执行完毕后执行。而BGREWRITEAOF指令执行过程中,客户端发送的SAVE, BGSAVE指令会直接被服务器拒绝。- 虽然这两组指令同步执行并不会出现竞争状态,但是处于性能考虑,同时执行会导致大量的磁盘IO,这并不是一个好的设计。
载入: Redis服务器在启动的时候就会自动载入RDB文件(前提是找到了RDB文件)。不过需要注意:
- 如果服务器开启了AOF持久化功能,则服务器会优先使用AOF文件来还原数据库状态。
- 只有AOF持久化功能被关闭的时候,服务器才会使用RDB文件来还原数据库状态。
- 服务器载入RDB文件期间,会一直处于阻塞状态,直到载入完毕。
自动间隔性保存
与SAVE不同,由于BGSAVE是一个不会让服务器主进程阻塞的指令,它可以做自动执行的操作。用户可以通过设置服务器配置的save选项,让服务器每个一段时间自动执行一次BGSAVE。例:save [time] [changes],意为在[time]秒之内,对数据库进行了至少[changes]次修改,BGSAVE便会自动执行。用户可以定义多个save选项,只要任意一个满足了条件,便会执行BGSAVE。
- 当用户没有手动设置保存条件时,服务器则会为
save选项设置默认条件
1 | |
书中还记录了具体底层代码的结构,这里不做详细赘述。
既然Redis服务器允许这类操作存在,那么必然也需要一些属性用于监视这些数据。针对这个问题,Redis中具有dirty计数器和lastsave属性:
dirty计数器:用于记录自上一次SAVE, BGSAVE命令之后,服务器对数据库状态(所有数据库)进行了多少次修改。这里有一点要注意 :SET message ...会让dirty计数器加1SADD database value1 value2 value3 ... valueN会让dirty计数器加N- 因此在创建有多组数据的类时(集合,列表,哈希,有序集合),
dirty计数器增加的量为数据量。
Redis的服务器周期性操作函数serverCron默认每个100毫秒就会执行一次,而BGSAVE的自动执行也是在这个函数中进行判断。
RDB文件结构
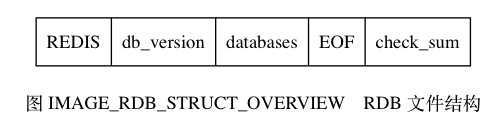
- RDB文件是一个二进制数据,因此文件中所有看起来像字符串的内容都不会以
\0结尾。 REDIS:由这五个字符组成的,类似于一个文件标识,用于快速识别该文件是一个RDB文件。db_version:一个四字节的字符串,用于表示该文件的版本号。现在似乎最新版本是0009,代表第九版RDB文件结构。databases:包含零个或任意多个数据库。以及数据库中的键值对数据。EOF:一个一字节的常量,用于标志RDB文件正文部分结束。check_sum:一个八字节长的无符号整数,保存这一个校验和。这个校验和是通过前四个部分的内容进行计算得出。在载入文件时,会根据该值与使用前四个部分再进行计算的值进行对比,判断该文件是否出错或损坏。
书中详细讲了database的组成,我这里用一个树结构直观地描述一下整体结构:
1 | |
-
SELECTDB:一字节,代表下一个部分是数据库号码 -
db_number:一、二或五字节,代表数据库号码。程序读取时会根据这个号码读入指定的数据库中。 -
key_value_pairs:-
EXPIRETIME_MS, ms:当该键被设有过期时间时才会存在。EXPIRETIME_MS常量长度为一字节,即充当了一个具有过期时间的键的标识,由告诉程序下一个要读入的是一个以毫秒为单位的过期时间ms -
TYPE:value的类型。长度为一字节,此为众多常量的其中一个:1
2
3
4
5
6
7
8
9
10REDIS_RDB_TYPE_STRING
REDIS_RDB_TYPE_LIST
REDIS_RDB_TYPE_SET
REDIS_RDB_TYPE_ZSET
REDIS_RDB_TYPE_HASH
REDIS_RDB_TYPE_LIST_ZIPLIST
REDIS_RDB_TYPE_SET_INTSET
REDIS_RDB_TYPE_ZSET_ZIPLIST
REDIS_RDB_TYPE_HASH_ZIPLIST
# 总而言之,就是在对象那一篇文章中讲到过的所有对象的encoding -
根据不同的
TYPE,value也不一样
-
-
key:该键值对的键,总是一个字符串对象 -
value:该键值对的值。这东西名堂多了,取决于TYPE的值。不过都很符合直觉。每一个都展开细讲有点没必要,想要仔细了解的可以去翻书看看,或者去这个网页:《Redis设计与实现》。这个实际上就是那本书的内容了,不过书中有些东西版本比较老。
书中的下一个部分介绍了RDB文件的解析,不过这个不是很重要。想看的可以自行去看看。不过这里推荐大家可以先去自己尝试一下创一个Redis服务器,往里面放一两个简单的数据,然后用od -c dump.rdb看一下文件里的内容。结合之前的知识,看看能不能看懂这个文件信息。
注意: 生成RDB文件时默认名称是dump.rdb
AOF持久化
与RDB文件担任的职责不同,AOF文件仅用于记录服务器所执行的写命令来记录数据库状态。
这里引用书中一个非常直观且简单的例子:
1 | |
在执行完这些命令之后,AOF文件中应该记录这些内容:
1 | |
简单的提示: 把每一个\r\n都看成是分隔符
这些命令的追加,一言以蔽之,就是每当客户端向服务器发送一个写命令,服务器就会将协议内容追加到aof_buf缓冲区的末尾。
AOF文件的写入与同步
如在前几个章节或文章中说过,Redis服务器进程就是一个事件循环。而在每一次循环结束之前,都会调用flushAppendOnlyFile函数,考虑是否要将aof_buf缓冲区的内容写入和保存到AOF文件中。而这个函数的行为取决于服务器配置的appendfsync选项:
always:将aof_buf缓冲区中的所有内容写入并同步[1]到 AOF 文件。- 最慢,但最安全。即便是故障停机,也只会丢失一个循环的AOF信息
everysec(默认值):将aof_buf缓冲区中的所有内容写入到 AOF 文件, 如果上次同步 AOF 文件的时间距离现在超过一秒钟, 那么再次对 AOF 文件进行同步, 并且这个同步操作是由一个线程专门负责执行的。- 折中的做法。故障停机也只会丢失一秒钟的AOF信息
no:将aof_buf缓冲区中的所有内容写入到 AOF 文件, 但并不对 AOF 文件进行同步, 何时同步由操作系统来决定。- 写入速度最快,但同步时间最长,并且最有可能丢失大量AOF数据。总的来说,听天由命。
AOF文件的载入与数据还原
AOF文件的载入与数据还原其实也是一个非常直观且易懂的流程:
- 创建一个不带网络连接的伪客户端
- 为什么?因为现在要操作的AOF文件,而不是真实的新命令
- 从AOF文件中分析并读取一条写命令
- 使用为客户端执行被读出的写命令
- 反复执行2,3,知道AOF文件中所有写命令都被处理完毕为止
那么可能会有几个问题:
- 开启新Redis服务器的时候,内部应是没有任何数据存在的。那假设之前这个服务器开了很久,AOF文件很大的话,这样子做是否高效?
- 经过AOF重写机制,能极大程度地缩小AOF文件的大小,同时也会简化还原数据时所需要的执行次数。
AOF文件重写
AOF文件重写的主要目的是为了删除冗余命令,合并命令以缩小AOF文件和简化数据还原时的程序复杂度。
基本操作方式是创建一个新的AOF文件,往里面写入内容以代替旧的AOF文件。
不过虽然这么说,但是实际上AOF文件的重写并不会对AOF文件本身进行任何读操作,而是通过检查当前数据库中的键值对,用SET等一句写命令,替代所有之前记录这个键值的多条命令。比如说:
1 | |
用正常的AOF文件写入逻辑,文件中将会有6个不同的,对同一个键值的写入命令。而通过使用AOF文件重写,将直接从数据库中读取键list的值,然后生成一条RPUSH list "C" "D" "E" "F" "G"来代替这六条写入命令。这一点,对任何类型的键都有效。
由于AOF文件与RDB文件所扮演的基本角色是一样的,目的都是要还原服务器数据库的数据,因此它完全可以将内部的指令全部简化为像SET, RPUSH, SADD这类简单的写入命令。 不过,它同样也会设置生成键过期时间的指令。
注意: Redis也考虑了缓冲区溢出的问题。因此,在处理列表,哈希表,集合,有序集合这四种可能会带有多个元素的键时,会先检查键所含元素的数量,基于redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD常量来决定是否要对同一个键进行多次命令。在目前版本中,这个常量为64。
AOF后台重写
写入操作通常会占用大量服务器的IO以造成服务器卡顿一类的性能问题。因此AOF的重写操作都是在Redis程序的子进程中执行。这便是BGREWRITEAOF命令。然而,也许在后台重写的过程中,主进程还在对数据库进行操作,因此Redis还需要处理这种情况下的数据不一致问题。
实际上解决方法也很简单,在开始执行AOF后台重写命令时,主进程(Redis服务器)会开启一个AOF重写缓冲区。该缓冲区所扮演的角色与AOF缓冲区相似,在Redis服务器执行完一个写命令之后,不光会将这个写命令发送给AOF缓冲区,还会发送给AOF重写缓冲区。这样一来,子进程中的AOF重写过程中也能够保证同步Redis服务器在这期间的新的写命令。
在子进程完成任务后,会向父进程发送一个信号,父进程收到信号后,执行以下操作:
- AOF重写缓冲区的内容写入到新的AOF文件中,以保证新AOF文件中的数据库状态与当前服务器的数据库状态一致
- 对新的AOF文件进行改名,并原子性地覆盖现有AOF文件,完成替换
- 现代操作系统中的写入与同步时两个东西。前者代表的是将内容写入到一个内存缓冲区中,后者才是真正地将内容刷到磁盘里。刷到磁盘(同步)的时机有很多种,当缓冲区被填满,超过了指定时限,人工强行同步等等。 ↩